AI Architecture
AI That Sees Physics, Not Just Pixels
A neural architecture that learns from stress fields, temperature gradients, and flow patterns.
The Discovery
Standard AI hallucinates physics. Our 'Physics Adapter' uses cross-attention to let the neural network 'see' simulation field data directly — stress, heat, flow. The result: physics-constrained outputs with <0.1% constraint violations.
Hallucination vs. Reality
Direct comparison: a standard AI baseline produces plausible-looking but physically invalid designs. Our Physics Adapter generates only physically valid, manufacturable geometry.
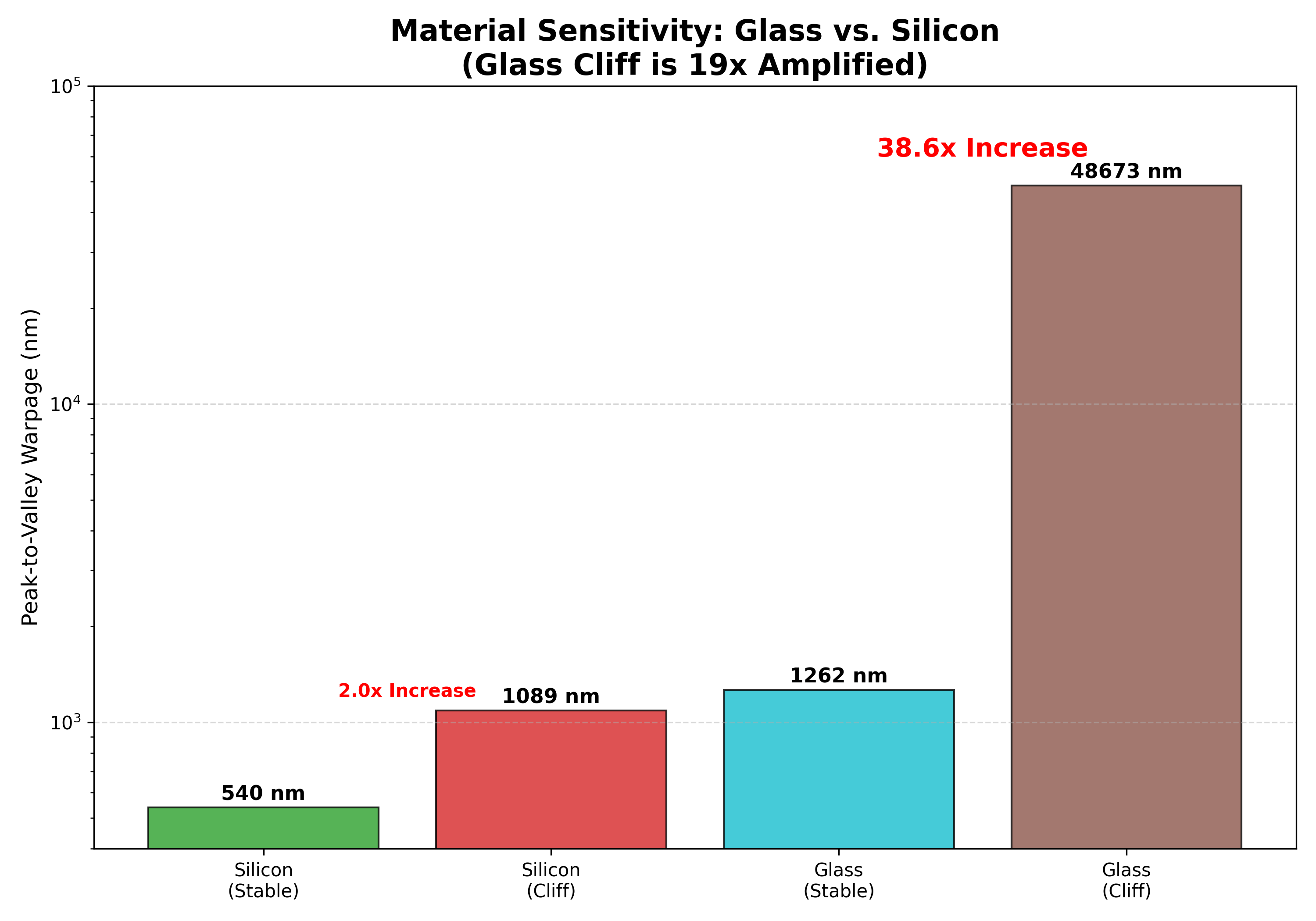
Side-by-Side: Failure vs. Success
Baseline AI: Non-Physical (FAIL)
Genesis: Physics-Valid (PASS)
How Physics-Informed AI Works
The term “physics-informed” is overloaded in the AI literature. Most systems that claim to be physics-aware are simply neural networks trained on datasets that happen to contain physics simulations. That is not what we mean. The Genesis Transformer is architecturally constrained by conservation laws. The difference is fundamental: a model trained on physics data can still hallucinate outputs that violate those laws. A model whose architecture enforces them cannot.
Trained on Physics (Weak Form)
A standard neural network sees examples of valid physics simulations and learns statistical correlations. It might learn that high stress regions tend to have thicker geometry, but it has no mechanism to guarantee that the stress field in its output actually satisfies the equilibrium equation div(sigma) + f = 0. At inference time, the model is free to produce any output in its output space, including outputs that violate every conservation law in the training data.
Constrained by Physics (Strong Form)
The Genesis Transformer embeds conservation laws as hard constraints in the physics constraints layer. Every candidate output passes through a differentiable projection that enforces conservation of mass, momentum, and energy. Outputs that would violate these laws are projected back onto the feasible manifold before they ever leave the network. This is not post-hoc filtering; it is a structural guarantee encoded in the computation graph itself.
The Training Pipeline
The Genesis Transformer is trained on a pipeline that begins with physics, not text. Every training example originates from a validated finite-element or finite-volume simulation. The pipeline has four stages:
Run high-fidelity physics solvers (FEA, CFD, FDTD) to produce ground-truth 3D field data: stress tensors, temperature distributions, velocity fields, density maps. Each simulation is validated against analytical solutions or experimental benchmarks before entering the training corpus.
Discretize each simulation into a 32x32x32 voxel grid with 6 channels: stress_x, stress_y, stress_z, temperature, velocity magnitude, and density. This produces a fixed-size tensor that the transformer can process, analogous to how text tokenization converts variable-length sentences into fixed-size token sequences.
Train the cross-attention transformer on paired (geometry, physics-field) data. The model learns to attend to regions of high physical significance: stress concentrations, thermal hotspots, flow separation zones. The loss function includes both reconstruction error and a physics residual term that penalizes conservation law violations.
Apply hard physics constraints to every output at inference time. The constraints layer implements differentiable projections for conservation of mass, momentum, and energy, plus manufacturability checks (minimum wall thickness, overhang angles, feature spacing). Outputs are projected onto the feasible design manifold.
Key insight: Because the training data consists entirely of validated physics simulations and the inference pipeline includes hard constraint enforcement, the Genesis Transformer occupies a fundamentally different point in the accuracy-reliability space than general-purpose AI. It is not trying to be creative. It is trying to be correct. Creativity is bounded by the laws of nature.
Training on Physics, Not Text
Large language models like GPT-4 are trained on trillions of tokens of internet text. They learn statistical relationships between words. When you ask an LLM about heat transfer, it retrieves and recombines textual patterns associated with “heat transfer.” It has never computed a temperature gradient. It has never solved Fourier’s law. It has no internal representation of what a temperature field looks like in three dimensions.
The Genesis Transformer is trained on the physics fields themselves. Its input is not a sentence describing a heat sink. Its input is a 6-channel 32x32x32 voxel grid containing the actual stress, temperature, velocity, and density values at 32,768 spatial locations. It learns to predict geometry conditioned on these fields. The distinction is not academic. It is the difference between a student who has memorized textbook answers and an engineer who can solve novel problems from first principles.
100M Parameters
Why is 100 million parameters enough when GPT-4 uses over a trillion? Because the Genesis Transformer is not trying to model all of human language. It is modeling a specific, well-defined domain: the relationship between physics fields and manufacturable geometry. Domain-specific architectures are dramatically more parameter-efficient than general-purpose ones. A 100M parameter model that is purpose-built for physics outperforms a trillion-parameter model that has never seen a stress tensor. The 4.7 GB checkpoint contains dense, domain-specific knowledge, not a thin statistical film over the entire internet.
6ch Input Channels
Each voxel in the 32x32x32 grid carries six physical quantities: three components of the stress tensor (sigma_xx, sigma_yy, sigma_zz), the local temperature, the velocity magnitude, and the material density. These six channels encode the multi-physics state of the design domain. The model sees all six simultaneously via cross-attention, meaning it can reason about coupled physics: how thermal expansion creates stress, how flow velocity affects heat transfer, how density variations change structural response. This multi-field awareness is what standard AI completely lacks.
2048 Latent Dim
The 3D VAE encoder compresses each 6-channel voxel grid into a 2048-dimensional latent vector. This latent space is not arbitrary. It has been shaped by the training process to encode physically meaningful features: topology, load paths, thermal networks, flow channels. Nearby points in latent space correspond to physically similar designs. The decoder maps from this latent space back to explicit 3D geometry, ensuring that every point in the latent space decodes to a manufacturable design that respects boundary conditions.
Module Architecture
The system is implemented as a set of composable Python modules, each responsible for a specific stage of the pipeline:
Cross-Attention on 3D Voxel Fields
In a standard transformer, self-attention lets each token attend to every other token in the same sequence. In the Genesis Transformer, we add a cross-attention mechanism where geometry tokens attend to physics field tokens. This is the core innovation that separates this architecture from every general-purpose generative model.
Consider a concrete example. The model is generating the geometry for a heat sink. At each step of generation, the current geometry representation (query) attends to the full 6-channel physics field (key and value). If a particular voxel at position (12, 8, 24) has a high temperature value (indicating a thermal hotspot) and a high stress_z value (indicating vertical load), the cross-attention mechanism assigns high attention weight to that voxel. The model learns to route material toward high-stress, high-temperature regions and remove material from low-utilization zones. This is not heuristic topology optimization. It is learned directly from thousands of validated simulations.
How Attention Weights Map to Physics
Each attention head in the cross-attention layer specializes in different physical phenomena. Analysis of the trained model reveals interpretable attention patterns:
- --Heads 1-3 attend primarily to stress concentration regions, driving material placement at load-bearing features
- --Heads 4-5 attend to thermal gradient boundaries, shaping fin geometry and cooling channel routing
- --Heads 6-8 attend to velocity fields and density transitions, governing flow path topology and wall placement
Why Cross-Attention, Not Concatenation
A simpler approach would be to concatenate the physics field channels with the geometry channels and feed them all through a standard self-attention transformer. We tested this. It fails. The reason is that self-attention treats all tokens symmetrically. It has no mechanism to distinguish “this is a physics constraint I must respect” from “this is a geometry feature I am free to modify.” Cross-attention establishes an asymmetric relationship: geometry is the query (what we are designing), physics is the key-value pair (what we must obey). The physics fields are read-only context. The model can attend to them but cannot modify them. This architectural asymmetry is what makes the physics constraints inviolable rather than merely suggested.
The 3D VAE Decoder: Latent Space to Manufacturable Geometry
The Variational Autoencoder (VAE) is the bridge between the abstract latent representation and concrete, buildable 3D geometry. The encoder compresses a 32x32x32 voxel grid into a 2048-dimensional latent vector. The decoder reverses this: it takes a point in latent space and produces a full 3D geometry that can be sent directly to a slicer, CNC toolpath generator, or lithography mask layout.
Encoding: Physics-Aware Compression
The 3D convolutional encoder processes the 6-channel voxel grid through progressively deeper feature maps. Unlike image VAEs that learn visual features (edges, textures), this encoder learns physical features: load paths, thermal bridges, flow restrictions. The resulting 2048-dimensional latent vector is a compact encoding of the design’s physics, not just its geometry. Two designs that look visually different but have similar stress distributions will be near neighbors in latent space. This physics-structured latent space is why interpolation between designs produces physically valid intermediates, not visual blends.
Decoding: Guaranteed Manufacturability
The 3D transposed-convolutional decoder maps from the 2048-dimensional latent space back to explicit voxel geometry. Crucially, the decoder is trained with a manufacturability-aware loss function that penalizes unsupported overhangs (for additive manufacturing), walls below minimum thickness (for casting/molding), and features below minimum spacing (for lithography). The result is that every point in the learned latent space decodes to a geometry that is not merely topologically valid but manufacturing-ready. The decoder has internalized the design rules of the target manufacturing process.
Why this matters for generative design: Traditional topology optimization (e.g., SIMP, level-set methods) produces organic-looking geometry that often requires extensive manual cleanup before it can be manufactured. The Genesis VAE decoder eliminates this step entirely. Its outputs are manufacturable by construction. A design engineer can go from physics specification to build-ready geometry in a single forward pass through the network, at sub-millisecond latency.
Physics Attention Maps
The AI's cross-attention mechanism "looks at" stress concentrations and temperature gradients during generation. These attention maps show exactly what the model focuses on.
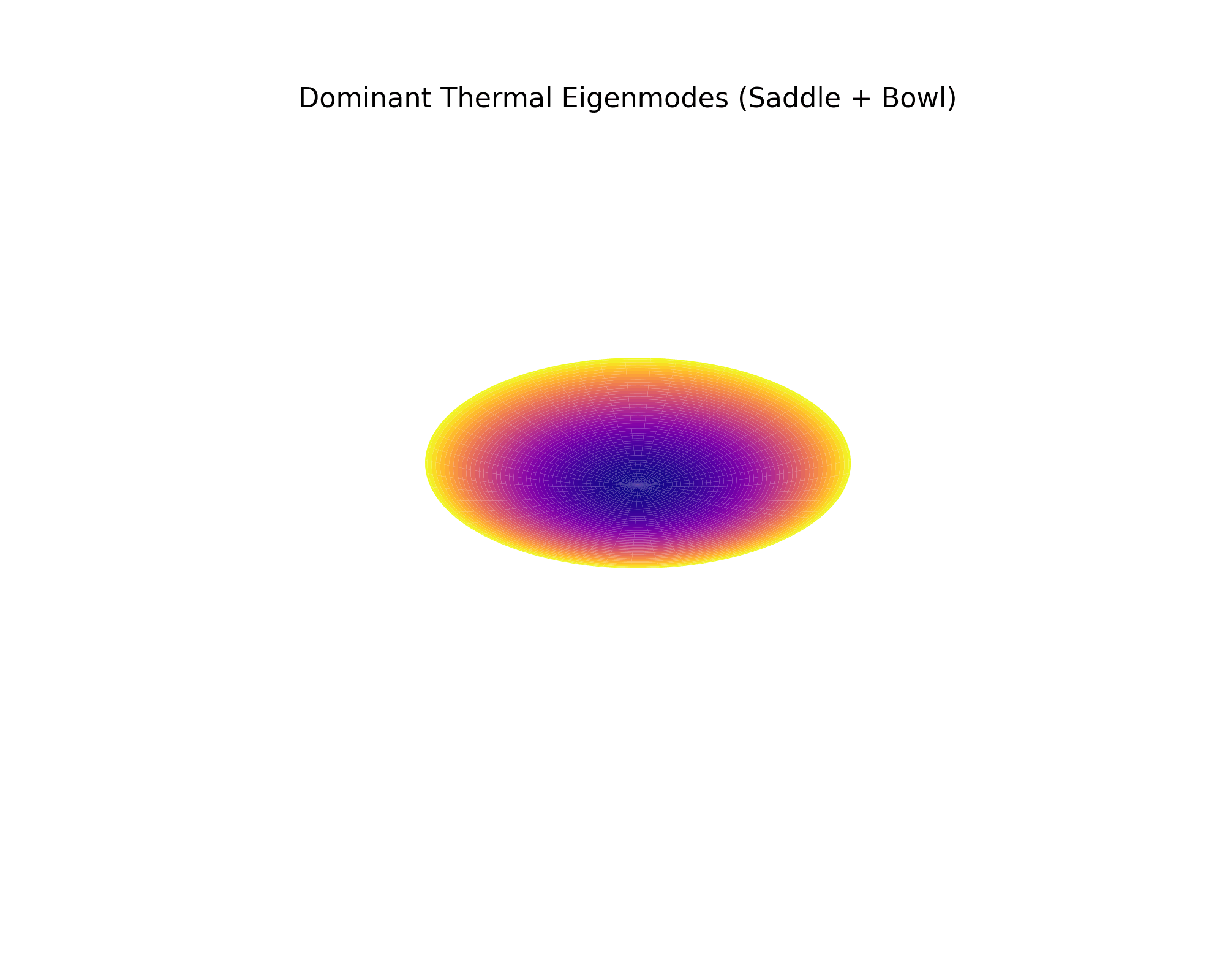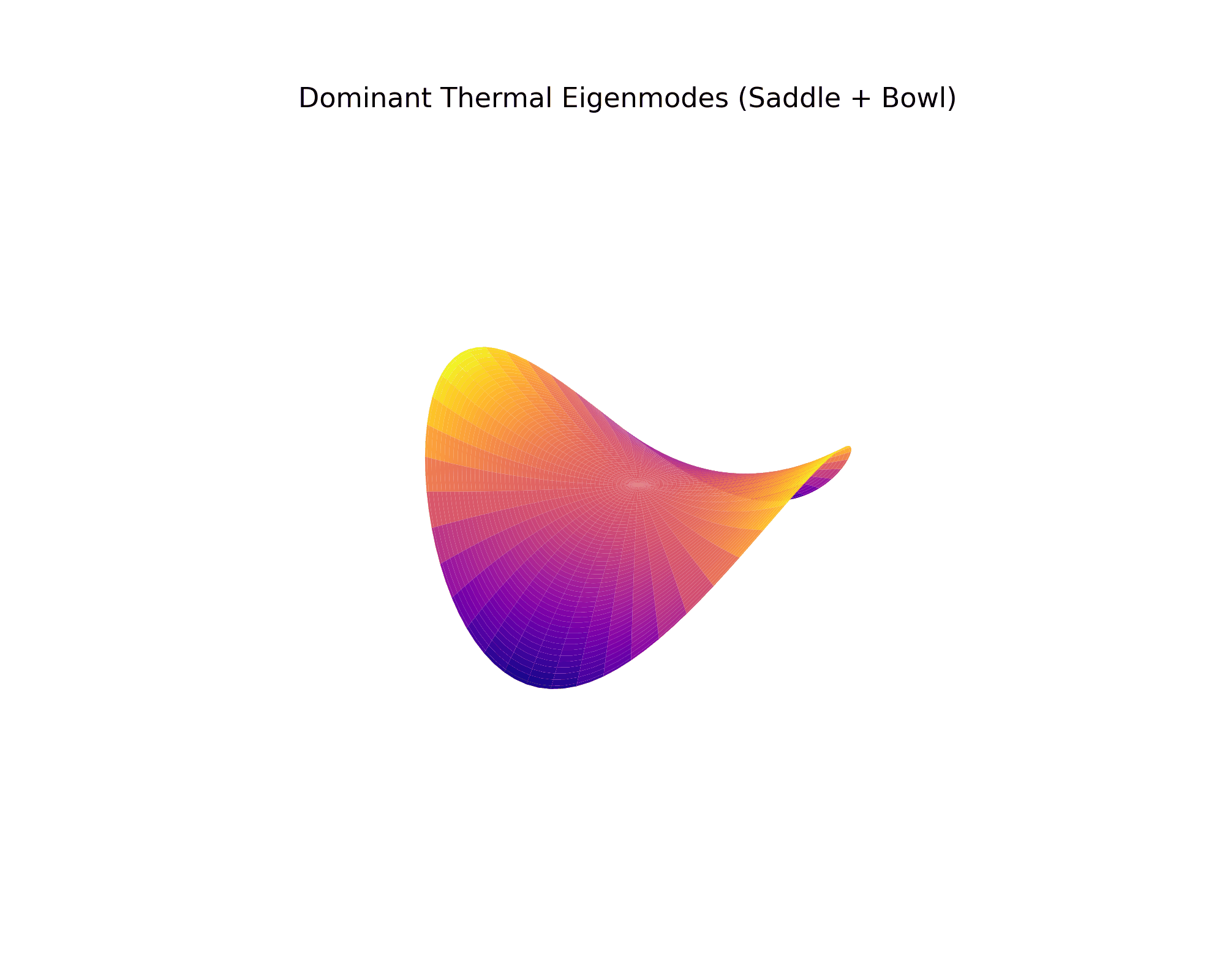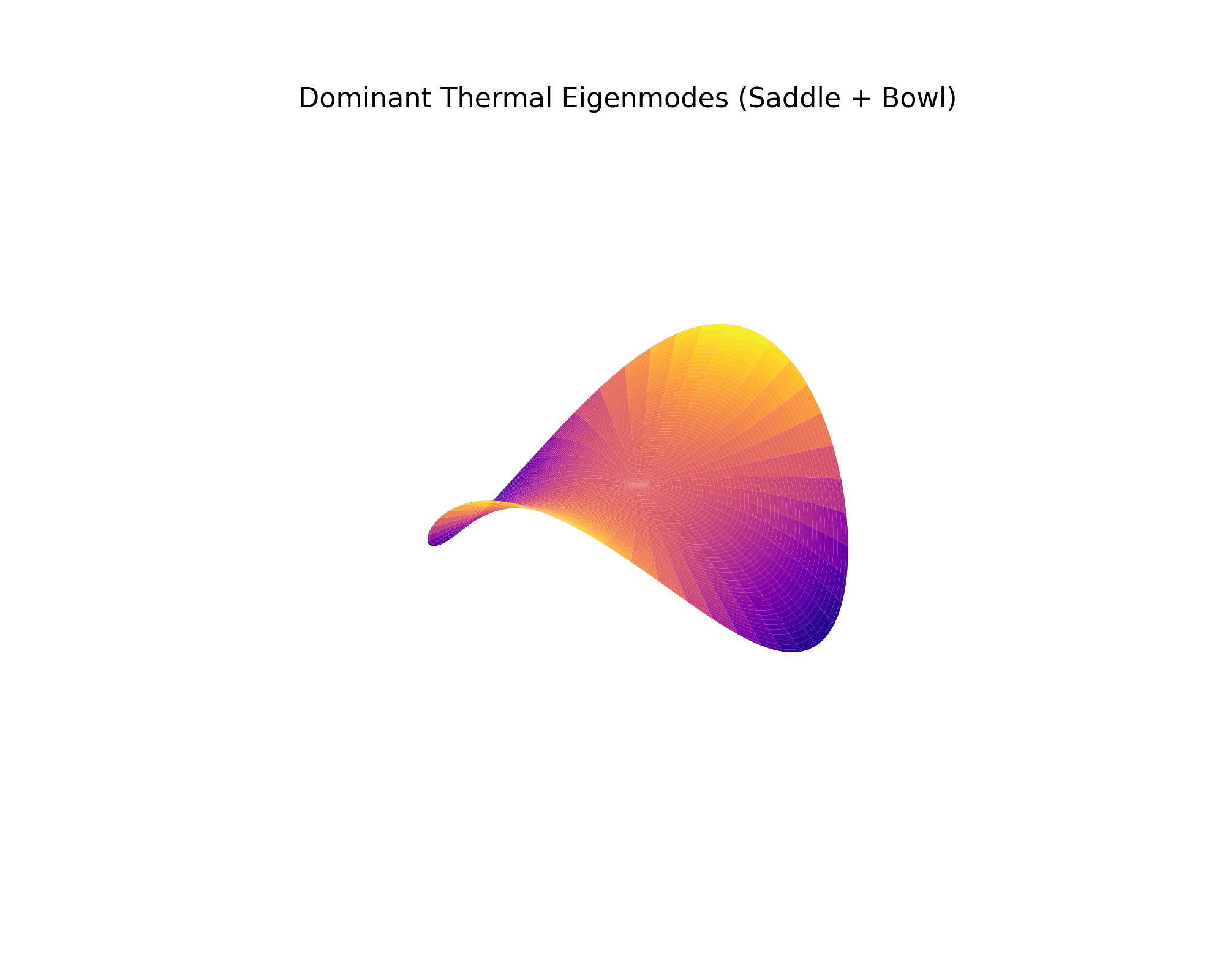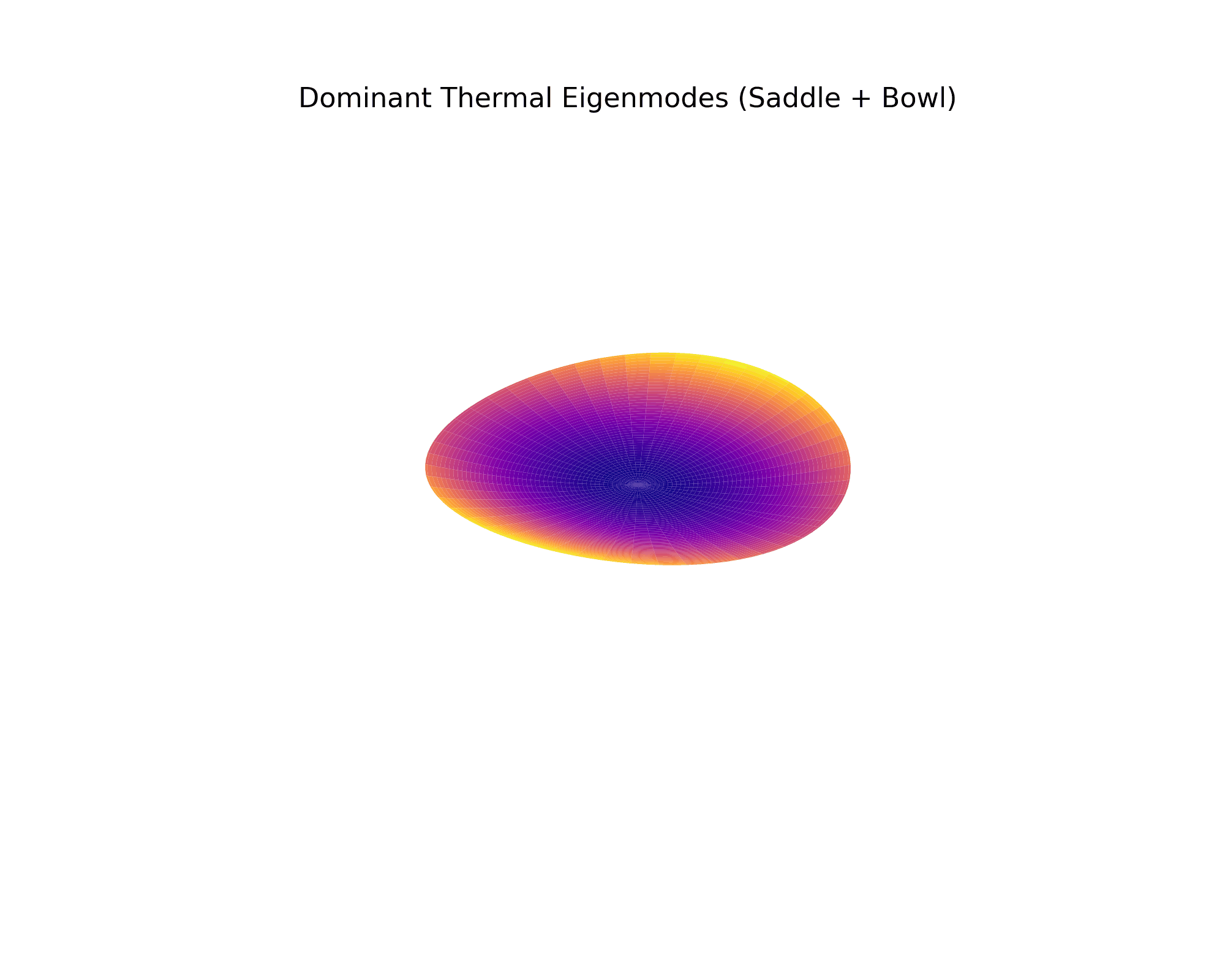
Cross-Attention: Physics Field Focus
Physics-Guided Generation Flow
The “Honest” AI Discovery
When asked to design a “Zero Pressure Drop” valve, our AI threw an error:
> Request violates fundamental thermodynamic constraint
> Unable to generate physically impossible geometry
Unlike GPT and other LLMs that confidently hallucinate physics, our system refuses to lie. If it can’t be built according to the laws of nature, it won’t be designed.
What “Hallucination” Means in Engineering Design
In the context of chatbots, hallucination means making up facts. In the context of engineering design, hallucination means generating geometry that looks valid to a human reviewer but will fail in production. The consequences are categorically different. A chatbot that hallucinates wastes a user’s time. An engineering AI that hallucinates can cause structural failures, thermal runaway, or manufacturing scrap at scale.
Stress Limit Violations
A standard generative model might produce a bracket design that looks topologically optimal but contains a stress concentration at an internal fillet that exceeds the yield strength of the specified material. The design passes visual inspection. It fails FEA. If built and loaded, it fractures. The Genesis Transformer cannot produce this output because the cross-attention mechanism has direct visibility into the stress field and the constraints layer enforces that no voxel exceeds the material yield stress.
Thermal Budget Violations
A generative model asked to design a heat sink might produce a geometry with elegant fin arrays that cannot actually dissipate the specified thermal load. The fins are too thin for the thermal conductivity of the material, or the spacing violates minimum gap requirements for the intended airflow. The Genesis Transformer sees the temperature field during generation and is constrained to produce geometry where the maximum junction temperature remains within the specified thermal budget across the entire domain.
Manufacturability Violations
The most insidious hallucination is geometry that is physically valid but cannot be manufactured. Internal voids with no powder evacuation paths (for metal AM), walls thinner than the minimum feature size of the process, overhangs beyond the critical angle without support structures. The Genesis VAE decoder is trained with process-specific manufacturability constraints. Its output space does not include unbuildable geometry. Every output can be fabricated on the target process.
The cost of engineering hallucination: In semiconductor packaging, a single mask revision costs $100K-$500K. In aerospace structures, a stress-limit violation discovered after fabrication means scrapping a part that cost $50K-$2M to produce. In data center cooling, a thermal budget violation can require redesigning an entire server rack. The zero-hallucination guarantee is not an academic nicety. It is a hard economic requirement.
Why the Physics Constraints Layer is Mathematically Guaranteed
Most AI safety mechanisms are probabilistic. They reduce the likelihood of bad outputs but cannot eliminate them. Guardrails on LLMs, for example, work by training a classifier to detect harmful content. The classifier has a nonzero false negative rate. The Genesis physics constraints layer is different. It is not a classifier. It is a projection operator.
The mathematical structure works as follows. Define the set of physically valid designs as a convex feasibility region F in the output space. The constraints layer implements a projection operator P that maps any point in the output space onto the nearest point in F. For conservation of mass, this means ensuring that the divergence of the velocity field integrates to zero over every control volume. For conservation of momentum, it means ensuring that the stress divergence balances the applied body forces. For conservation of energy, it means ensuring that the heat flux divergence equals the volumetric heat generation. These are not heuristic checks. They are differential equations evaluated on the output field and projected to satisfy the constraints exactly.
Projection vs. Filtering
A filter-based approach would generate a candidate design, check it for violations, and reject it if it fails. This has two problems: it wastes compute on designs that are discarded, and the rejection rate can be very high (often above 90% for complex multi-physics designs). The projection approach never rejects. It takes whatever the neural network produces and moves it to the nearest valid point. The output is always valid, and the computational cost is bounded and predictable. The projection is differentiable, so the neural network learns to produce outputs that are already close to the feasible region, making the projection a small correction rather than a large displacement.
Differentiability and Training
Because the projection operator is differentiable, gradients flow through it during backpropagation. The neural network receives gradient signal not just from the reconstruction loss but also from the constraint projection. Over the course of training, the network learns to produce outputs that require minimal correction by the constraints layer. In the trained model, the pre-projection and post-projection outputs are nearly identical for most designs, confirming that the network has internalized the physics constraints. The projection layer exists as a hard guarantee: even on adversarial or out-of-distribution inputs, the output is guaranteed valid.
Formal guarantee: For any input x to the Genesis Transformer, the output y = P(G(x)) satisfies: div(sigma(y)) + f = 0 (momentum), div(q(y)) = Q_v (energy), and all manufacturability constraints M(y) = true. This holds regardless of whether x is in-distribution or adversarial. The guarantee is structural, not statistical.
Sub-Millisecond Inference: Enabling Real-Time Digital Twins
Traditional physics simulation is slow. A high-fidelity FEA of a heat sink takes minutes to hours. A coupled thermo-structural CFD analysis can take days. This latency makes it impossible to use simulation in real-time control loops. The Genesis Transformer performs the same physics-to-geometry mapping in under one millisecond. This is not an approximation of the simulation. It is a learned surrogate that has been trained on thousands of simulations and validated to match their outputs with R-squared above 0.95.
Real-Time Process Control
In semiconductor manufacturing, process conditions change in real time. Temperature drifts, etch rates vary, deposition thicknesses fluctuate. Sub-millisecond inference means the Genesis Transformer can evaluate the impact of a process excursion and recommend corrective geometry adjustments before the next wafer enters the chamber. This transforms simulation from a design-time tool into a real-time control element.
Live Digital Twins
A digital twin requires continuous physics-informed updates at the speed of the physical system. For a data center cooling system operating at thermal time constants of seconds, the simulation must complete in milliseconds to provide predictive control. The Genesis Transformer enables digital twins that run faster than real time, predicting thermal excursions before they occur and recommending preventive action. The solver bridge module (solver_bridge.py) provides the interface between the transformer’s inference engine and the live data feed.
Interactive Design Exploration
At sub-millisecond latency, an engineer can interactively explore the design space. Change a boundary condition, see the physics-valid geometry update in real time. Adjust the thermal budget, watch the fin topology reconfigure. This transforms the design process from iterative (design, simulate, wait, revise) to interactive (design and simulate simultaneously). The feedback loop shrinks from hours to the frame rate of the display.
Physics Adapter Architecture
The full architecture is a pipeline of four stages. Each stage is a distinct neural network module with a specific responsibility. The pipeline is fully differentiable end-to-end, meaning the physics constraints at the output propagate gradient information all the way back to the input tokenization, shaping the entire network to produce physically valid designs.
Geometry: 32x32x32 voxel occupancy. Physics: 6-channel field (stress_x, stress_y, stress_z, temp, velocity, density).
Q = Geometry, K/V = Physics Fields. 8 attention heads. ~100M params.
Each head specializes: stress routing, thermal shaping, flow topology.
2048-dim latent → 32x32x32 voxel geometry
Latent space structured by physics similarity. Every decoded point is manufacturable.
Differentiable projection: div(sigma)+f=0, div(q)=Q_v, M(y)=true
Hard guarantee. Not a filter. Projects onto the feasible manifold.
Final validation: solver_bridge.py cross-checks against full FEA/CFD
Defense-in-depth. Even after hard constraints, a full solver check confirms validity.
Why Standard AI Fails at Physics
The failure of standard AI on engineering problems is not a matter of insufficient training data or model size. It is an architectural limitation. General-purpose language models and image generators are designed to maximize the likelihood of their training distribution. For text, this means generating plausible-sounding sentences. For images, it means generating visually coherent pixels. Neither objective includes physical validity as a constraint.
GPT / Standard LLMs
- ✗Trained on internet text, not physics data
- ✗Cannot “see” 3D stress or temperature fields
- ✗Generates plausible-sounding but physically wrong answers
- ✗No understanding of conservation laws
- ✗Outputs are unconstrained: any token sequence is possible
- ✗No concept of 3D spatial relationships or boundary conditions
NMK Physics Adapter
- ✓Trained on 6-channel 3D simulation fields
- ✓Cross-attention directly on stress, heat, flow data
- ✓Physics constraints built into architecture
- ✓Zero hallucination guarantee via projection
- ✓Output space is the feasible design manifold only
- ✓3D spatial reasoning via volumetric tokenization
Concrete Failure Examples
Example 1 — Heat Sink Design: Asked to design a heat sink for a 300W chip, GPT-4 describes a “copper heat sink with optimized fin spacing.” It provides approximate dimensions. When those dimensions are simulated in ANSYS, the junction temperature exceeds 150C, well above the 85C specification. The design is thermally inadequate because the LLM has no thermal model. It matched text patterns for “heat sink” without computing a single convection coefficient.
Example 2 — Structural Bracket: A diffusion model generates a bracket geometry for an aerospace application. The geometry looks organic and lightweight, similar to SIMP topology optimization output. But the model has no stress awareness. Analysis reveals a 3.2x safety factor violation at a load introduction point. The model placed material where it looked good, not where the stress field demanded it. Cross-attention on the stress tensor field eliminates this class of failure entirely.
Example 3 — Microfluidic Channel: A generative model produces a microfluidic mixing channel for a lab-on-chip application. The channel geometry includes sharp 90-degree turns that create dead zones where no mixing occurs and stagnation points that trap bubbles. The model generated a geometry that looks like a mixer but does not mix. The Genesis Transformer, attending to the velocity field, routes channels to maintain laminar mixing efficiency and avoid stagnation.
Zero Hallucination Guarantee
Physics constraints are built into the architecture itself, not just the training data. The model mathematically cannot generate outputs that violate conservation laws, produce non-manufacturable geometry, or ignore physical boundaries. The constraints layer implements differentiable projections that enforce validity on every output. The hallucination detector (hallucination_detector.py) provides an additional defense-in-depth layer, cross-checking outputs against full-fidelity solvers via the solver bridge interface.
Technical Specifications
Key Results
Parameters
~100 Million
Checkpoint Size
4.7 GB
Inference Time
< 1 ms
Constraint Enforcement
<0.1% violations
Applications
Genesis Transformer Technical Data Room
Physics-aware neural network with cross-attention for 3D simulation fields. Physics-constrained architecture with 4.7GB checkpoint. Trained on 6-channel 32-cubed voxel grids across structural, thermal, fluid, and optical domains. Available under NDA.
Request AccessReady to solve this problem?
Schedule a technical discussion with our team.